Command-line tool
The ftm command generates, transforms, and exports streams of entities in line-based JSON. Typical uses:
- Convert structured tables (CSV, SQL) into entities by applying a mapping.
- Reshape, aggregate, validate, or filter an existing entity stream.
- Export a stream to another format — CSV, Excel, Gephi GEXF, Cypher for Neo4J, or RDF.
Every command reads from stdin and writes to stdout unless told otherwise, so commands chain with pipes. Almost every command accepts -i/--infile and -o/--outfile; pass - to force stdin or stdout explicitly.
Installation
ftm ships with the followthemoney Python package:
followthemoney transliterates text between scripts to support fuzzy name comparison, which requires the pyicu bindings and a system-level ICU library. On Debian-based systems:
For other platforms, see the pyicu installation notes.
The entity stream format
Commands exchange entities as newline-delimited JSON — one entity object per line, no pretty-printing. Files in this format use the extension .ijson or .ftm. A single entity looks like this:
Streams can be piped through multiple commands without decoding overhead, and large files can be processed incrementally. If you need a human-readable view, pipe through ftm pretty.
The writer always emits id as the first key in each line. Because the lines are sortable as plain text (every line starts with {"id":"<id>"), a standard sort pipeline orders an entity stream by ID without any JSON-aware tooling. The same property holds for line-based statement streams, which begin with {"canonical_id":"<id>".
This matters because Unix sort is fast, uses external merge sort to spill to disk when the input exceeds memory, and parallelizes across cores with --parallel. It scales to datasets of tens or hundreds of gigabytes without special infrastructure, which is what makes ftm sorted-aggregate and ftm aggregate-statements practical beyond what ftm aggregate can handle in memory.
Generating entities from tables
Executing a mapping
Mappings project structured data (CSV or SQL) into FollowTheMoney (FtM) entities according to a YAML mapping file. Run a mapping with ftm map:
curl -o md_companies.yml https://raw.githubusercontent.com/alephdata/aleph/main/mappings/md_companies.yml
ftm map md_companies.yml > moldova.ijson
This produces a stream of Company, LegalEntity, and relational entities covering Moldovan companies and their directors.
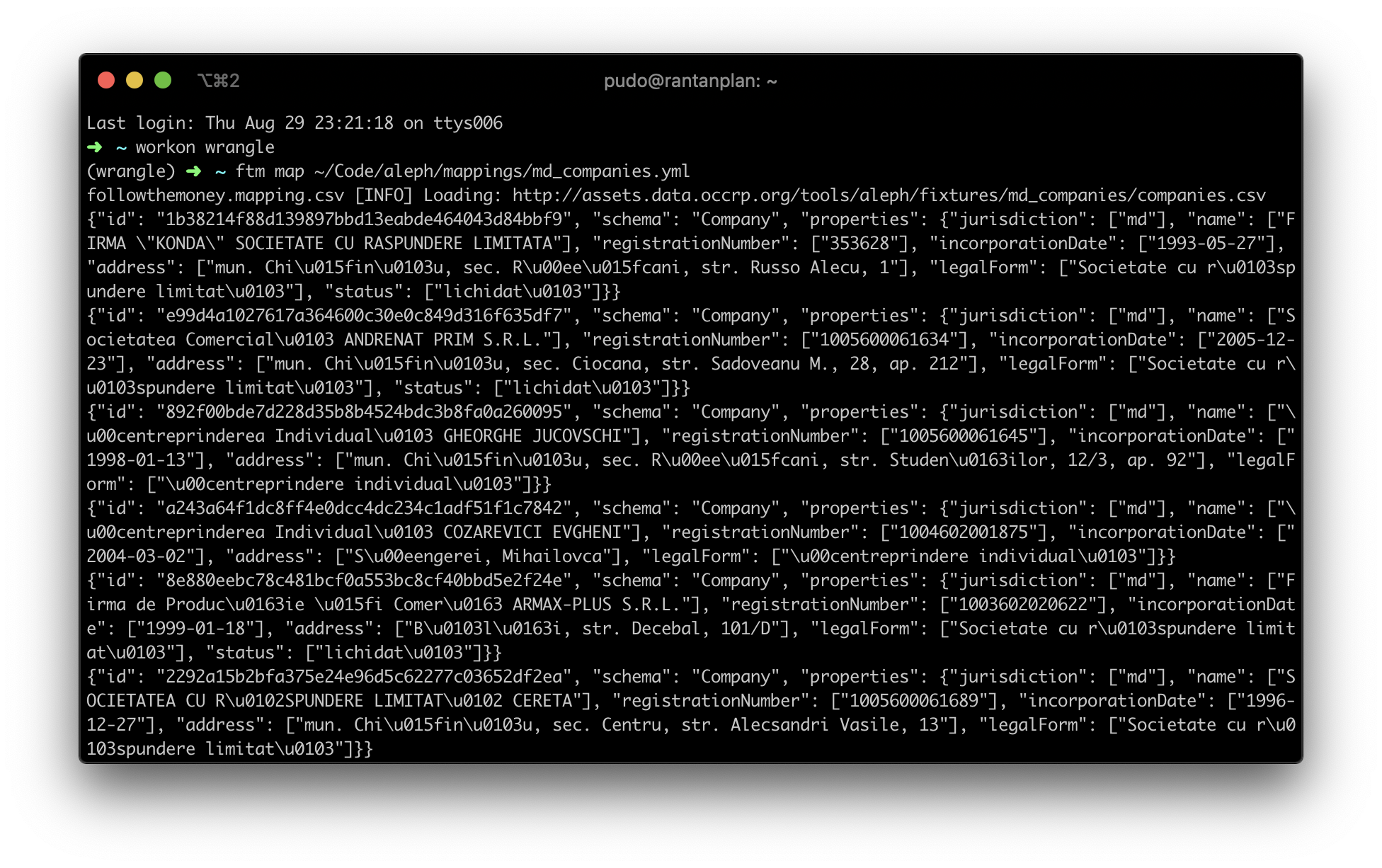
By default, ftm map signs every entity ID with the dataset's namespace, so IDs are unique within that dataset. Pass --no-sign to emit bare IDs instead — useful when downstream tools handle their own namespacing, or when you want the IDs to match across producers.
The dataset name comes from the top-level key in the mapping file. Override it with -d/--dataset when generating the same entities under a different dataset label:
A mapping often generates multiple fragments per entity — one from each query that touches the entity. See Aggregating fragments for how to merge them.
Mapping from a local CSV
ftm map-csv runs the same logic against CSV data piped in on stdin, ignoring any csv_url in the mapping file:
This is the right tool when the source data is local, private, or dynamically produced.
Mapping file structure
See the mappings reference for the YAML schema, including keys, filters, property transformations, and multi-table joins.
Validating and formatting streams
Re-parsing and validating
ftm validate re-parses an entity stream, running every property value through its type's cleaner and dropping invalid values. Use it as a safety net before loading data into an index or a downstream system:
If a producer emits unclean data (stray whitespace, invalid country codes, malformed dates), validation normalizes what it can and drops the rest.
Formatting for humans
ftm pretty indents each entity over multiple lines and is intended for eyeballing a stream in a terminal:
Do not feed the output back into another ftm command — indented JSON is not a valid entity stream.
Dumping the schema model
ftm dump-model writes the full FtM schema definition as a single JSON document:
This is the same model described by the schema explorer, serialized for tools that want to consume it programmatically.
Exploring the schema model
Where ftm dump-model emits the entire model at once, ftm ref lets you browse it one question at a time: which schemata exist, what properties a Person accepts, what type a property holds, what values an enum allows. It reads the model compiled into the installed followthemoney package, so it is always in sync with your version, works offline, and needs no API key. It is built for coding agents and humans who want an answer without reading the YAML sources or piping dump-model through jq.
Every ref command prints a table when attached to a terminal and JSON when piped or when --json is passed. So ftm ref schema Person is readable at a prompt, and ftm ref schema Person | jq produces JSON for tooling:
ftm ref # model overview + the subcommand index
ftm ref schemata # every schema, with matchable/abstract flags
ftm ref schemata --matchable # only schemata that can be matched
ftm ref schema Person # one schema, with all inherited properties
ftm ref types # every property type
ftm ref type country # one type, including its enum values
ftm ref prop Person:nationality # one property's full definition
ftm ref schema NAME lists the complete property set: own properties plus everything inherited from ancestor schemata. That is exactly the set of fields you can set on an entity of that schema. Stub (reverse-edge) properties are hidden by default; pass --stubs to include them. A property is addressed by its qualified Schema:property name, and inherited names resolve against the schema you ask about: ftm ref prop Person:name works even though name is defined on Thing.
Unknown names produce a Did you mean: …? suggestion and exit with a usage error, so a mistyped schema or property fails fast rather than silently returning nothing.
Namespace signing
ftm sign applies an HMAC signature to every entity ID in a stream, scoping the IDs to a named namespace:
Pass the namespace key with -s/--signature. Omitting it passes IDs through unchanged. Entity-typed property values are rewritten alongside the top-level IDs, so cross-entity references stay consistent within the namespace.
Use this when ingesting into a system (OpenAleph, multi-tenant yente) that expects signed IDs but your producer does not sign on emission.
Aggregating fragments
When a mapping or pipeline emits multiple records for the same entity ID, those records need to be merged before indexing. Two commands handle this:
ftm aggregatebuffers the entire stream in memory, merging fragments as they arrive. Order-independent but memory-bound.ftm sorted-aggregatewalks the stream once, buffering one entity at a time and merging any incoming fragment whose ID matches the buffered one. It emits the buffered entity as soon as a different ID appears. This runs in constant memory, but it only merges fragments whose occurrences are adjacent in the input. If the input is not sorted by ID, non-adjacent fragments of the same entity pass through unmerged without any warning.
For streaming aggregation on a sorted input, Unix sort is sufficient because each JSONL line begins with the id field:
Warning
ftm aggregate holds the entire dataset in memory. For datasets that exceed available RAM, sort the stream first and use ftm sorted-aggregate, or use an on-disk store (see Aggregating large datasets).
Filtering entities
ftm sieve removes schemas, properties, property types, or datasets from a stream:
# Drop all Passport entities
cat entities.ijson | ftm sieve -s Passport > filtered.ijson
# Strip note properties and phone numbers
cat entities.ijson | ftm sieve -p notes -t phone > redacted.ijson
# Keep only entities that are in dataset A but not dataset B
cat entities.ijson | ftm sieve -d 'a-b' > scoped.ijson
The -d/--datasets expression uses the dataset query syntax: a|b for union, a-b for difference, a&b for intersection.
Statement-based workflows
The statement data model records each claim about an entity as an individual row with provenance. Three commands move between entity streams and statements:
ftm statementsdecomposes an entity stream into a statement table.ftm format-statementsconverts statement tables between CSV, Parquet, and other formats.ftm aggregate-statementsrolls a sorted statement table back into an entity stream.
A typical pipeline:
# Entities → statements (CSV, attributed to dataset 'md_companies')
cat moldova.ijson | ftm statements -d md_companies > statements.csv
# Statements → entities, reconstructing full records
ftm aggregate-statements -i statements.csv > rebuilt.ijson
ftm aggregate-statements expects the statement stream to be sorted by the canonical entity ID. If it is not, pre-sort it the same way as for ftm sorted-aggregate.
Exporting to other formats
Tabular exports: CSV and Excel
Each FtM schema has a distinct set of properties, so tabular exports produce one table per schema: Person.csv, Company.csv, Ownership.csv, and so on.
Write to an Excel workbook:
Warning
Excel has a hard limit of roughly one million rows per sheet, and most office programs struggle with workbooks larger than a few hundred megabytes. Export only small- and mid-size datasets to Excel.
Write a directory of CSV files:
Each file in OFAC/ is named after its schema and contains one row per entity of that schema.
Graph exports: Cypher, GEXF, Neo4J bulk
FtM sees every unit of information as an entity with properties. To analyze a stream as a graph, you need to decide which entities and which property types become nodes and edges:
- Some schemas (
Directorship,Ownership,Family,Payment,Membership,Email) carry edge annotations and naturally become edges between their referenced entities. - Entity-typed properties (for example,
Email:emitters) also form edges. - Some property types (
email,identifier,name,address) can be reified into nodes of their own, with edges from each entity that carries that value. Pass these with repeated-e/--edge-typesflags.
Cypher for Neo4J
Export a Cypher script that loads the data into a running Neo4J instance:
To reify specific property types into their own nodes:
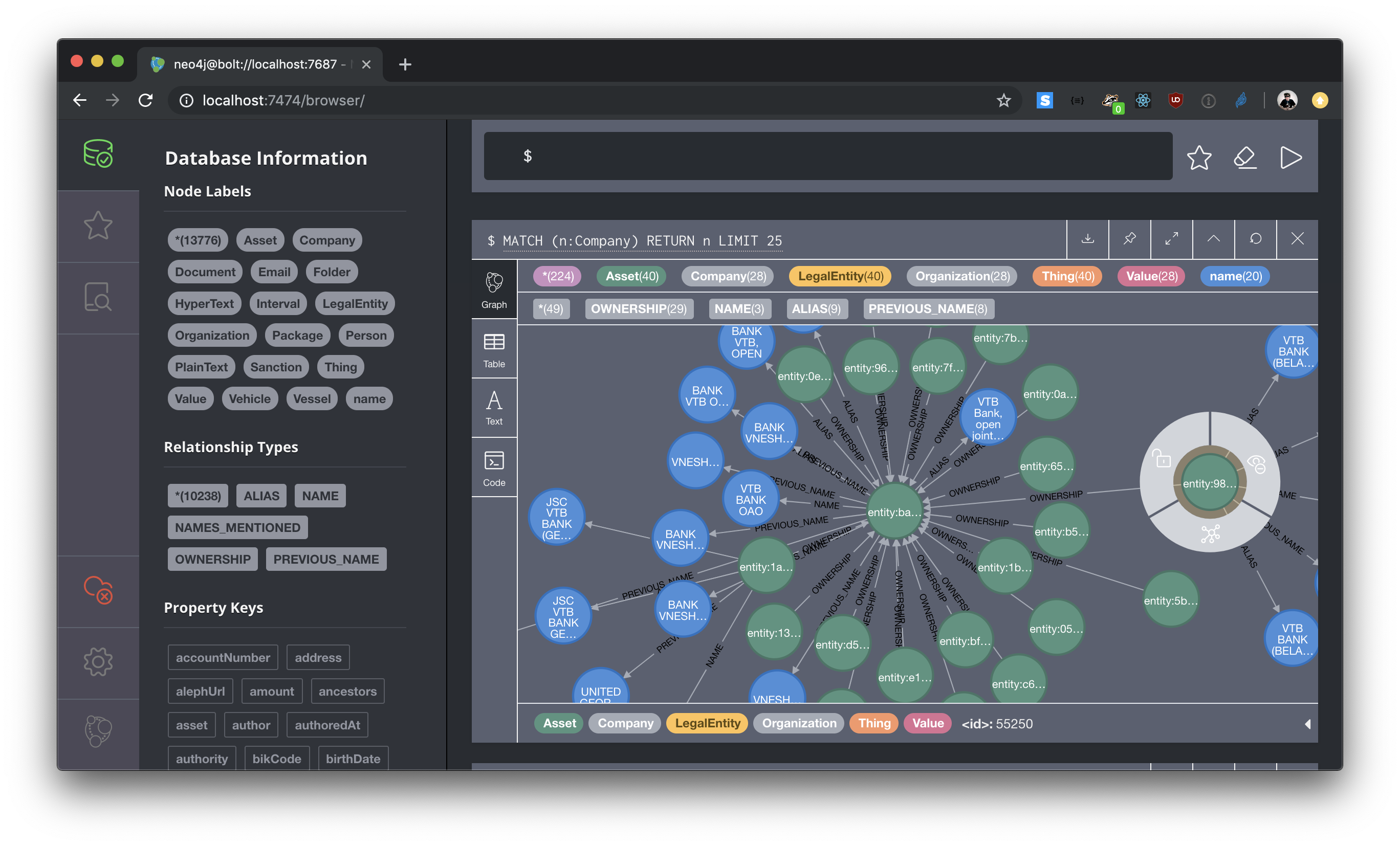
When working with data that contains document folder hierarchies (Aleph-style), the folder structure can dominate any path analysis. Remove it with Cypher:
MATCH ()-[r:ANCESTORS]-() DELETE r;
MATCH ()-[r:PARENT]-() DELETE r;
MATCH (n:Page) DETACH DELETE n;
// Delete reified value nodes that connect to only one entity:
MATCH (n:name) WHERE size((n)--()) <= 1 DETACH DELETE (n);
MATCH (n:email) WHERE size((n)--()) <= 1 DETACH DELETE (n);
MATCH (n:address) WHERE size((n)--()) <= 1 DETACH DELETE (n);
To reset the database:
Neo4J bulk import
For datasets too large for interactive cypher-shell loading, produce a directory of CSV files plus a shell script that invokes neo4j-admin import:
This requires stopping the Neo4J server and running the generated script against an empty database.
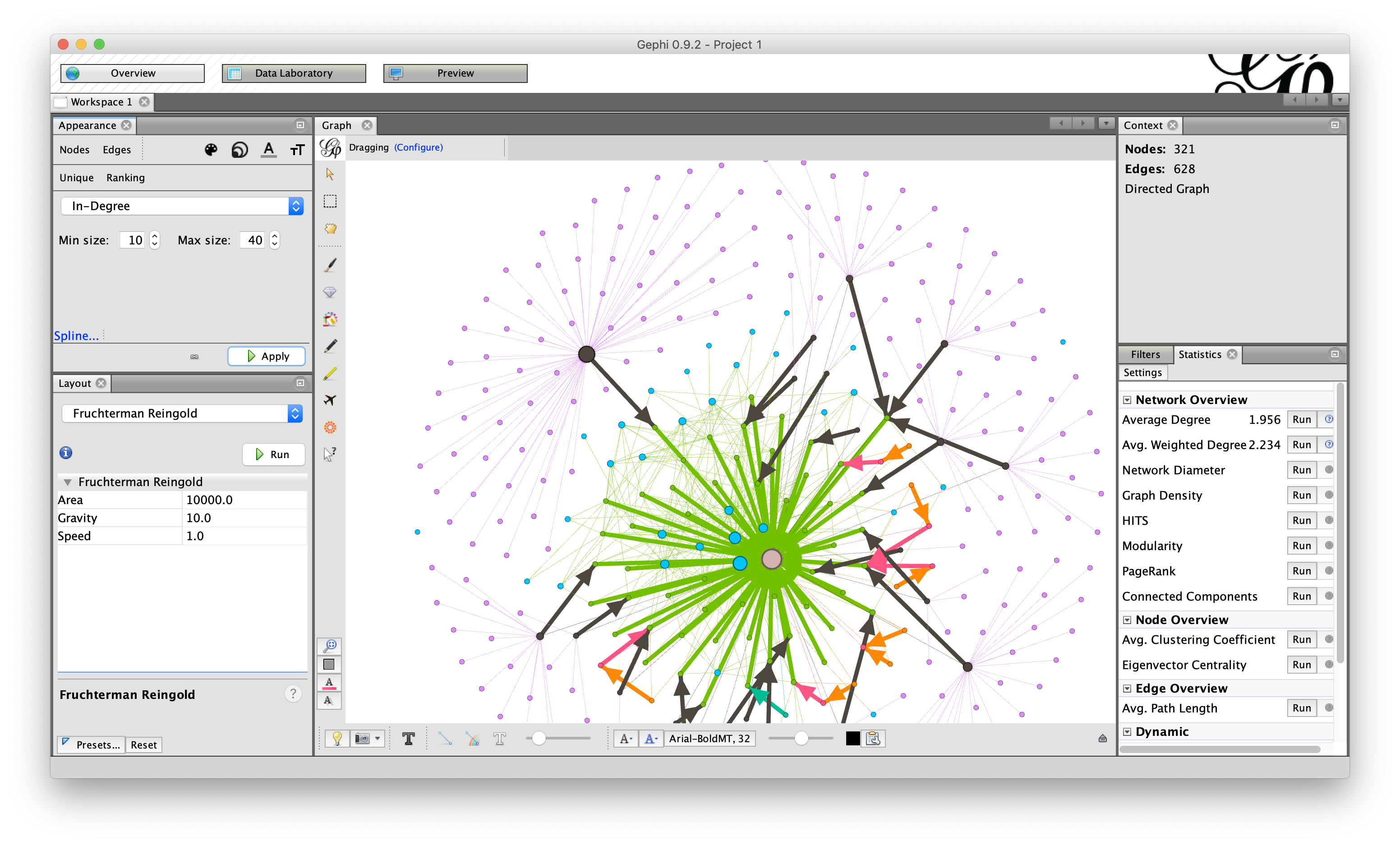
GEXF for Gephi
GEXF is the graph format used by Gephi and related tools. Use it for quantitative graph analysis (centrality, PageRank, force-directed layouts) on graphs of tens of thousands of nodes:
RDF export
Entity streams can be exported as NTriples:
The exporter maps each property to a fully qualified RDF predicate by default; pass --unqualified to emit short predicate names instead. The underlying FtM ontology is also published as RDF/XML, with mappings to FOAF and related vocabularies.
Aggregating large datasets
ftm aggregate holds the full dataset in memory, which is impractical beyond tens of millions of entities or when fragments are produced by multiple workers. The separate followthemoney-store package provides on-disk aggregation backed by SQLite or PostgreSQL.
Install with SQLite support:
With PostgreSQL, which supports upserts and performs better under write contention:
pip install followthemoney-store[postgresql]
export FTM_STORE_URI=postgresql://localhost/followthemoney
A typical write-then-iterate flow:
cat us_ofac.ijson | ftm store write -d us_ofac
ftm store iterate -d us_ofac > aggregated.ijson
ftm store delete -d us_ofac
Warning
When aggregating entities with very large text fragments, a per-entity size limit applies. Entities larger than 50 MB of raw text have additional fragments discarded with a warning written to stderr.
Extending the CLI
ftm discovers additional commands through the followthemoney.cli Python entry-point group. Packages that install Click commands under this group appear automatically in ftm --help after installation. followthemoney-store registers the ftm store subcommand this way, and zavod adds its own commands in environments where it is installed.